Precision AI Transcription
Experience accurate AI transcription that identifies speakers and adds timestamped transcripts automatically. Perfect for journalists, researchers, and legal professionals.
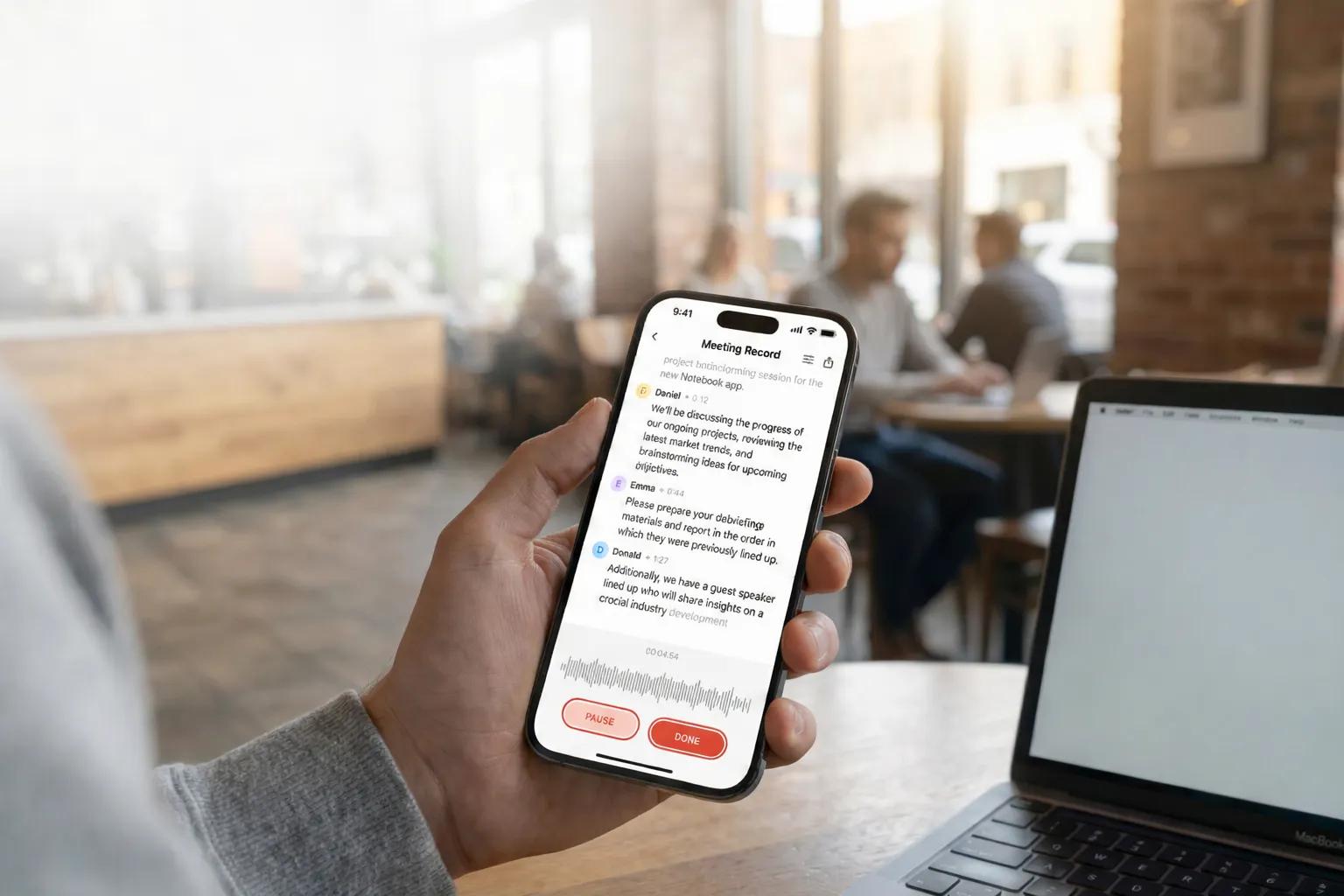
99% Transcription Accuracy
Leverage state-of-the-art audio to text converter technology to capture every nuance. HyNote achieves 99%+ accuracy on clear audio, rivaling professional human transcribers at a fraction of the cost and time. Our ensemble AI models, trained on millions of hours of diverse audio, combine multiple transcription engines to deliver the best results. Technical terminology, proper nouns, and industry jargon are captured correctly. Contextual understanding knows "Java" in programming refers to the language, while in travel it refers to the island. A 60-minute transcript contains approximately 9,000 words. At 99% accuracy, you'll find roughly 90 words that need review—mostly punctuation preferences. You spend minutes reviewing, not hours correcting.
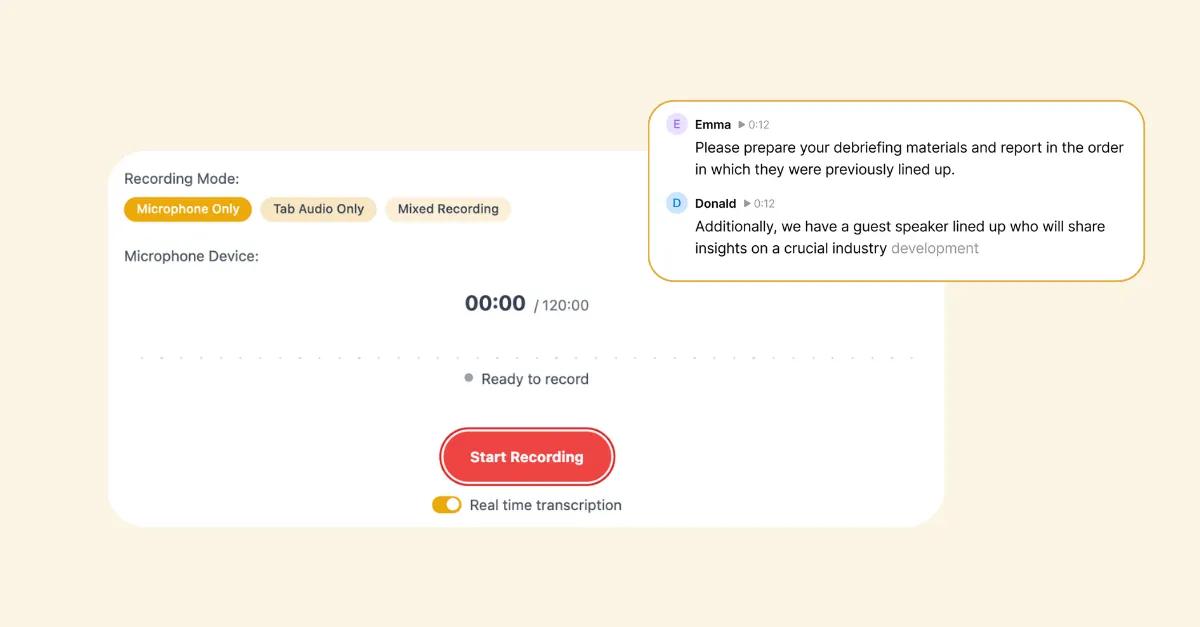
Smart Speaker Labeling
Automatically distinguish between multiple voices in group interviews or panel discussions. Our intelligent speaker diarization technology identifies different speakers, labels them automatically, and handles overlapping speech with 94% accuracy. Voice fingerprinting learns recurring speakers and auto-labels them in future recordings. Once you've identified "Speaker 1" as "Sarah from Marketing," she'll be automatically labeled subsequently. Confidence scoring flags uncertain attributions for your review, and the system learns from corrections. Journalists quote sources accurately. Researchers attribute quotes in qualitative studies. Managers track who committed to what in meetings.
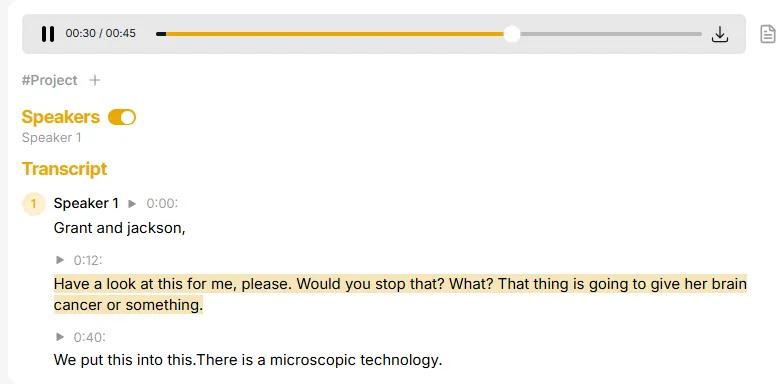
Interactive Timestamps
Click any word in the transcript to jump to that exact moment in the original audio recording. Every word becomes a navigation tool, transforming how you review and verify transcripts. Search for a keyword to find all mentions. Click any mention to hear the surrounding context. Select the exact quote you want and copy it with an automatic timestamp citation. What used to take 15 minutes of scrubbing through audio now takes 30 seconds. Share specific moments with links that start playback at the exact time. "Check what the client said at 23:47" becomes a clickable link. Your written analysis stays connected to the source material forever.
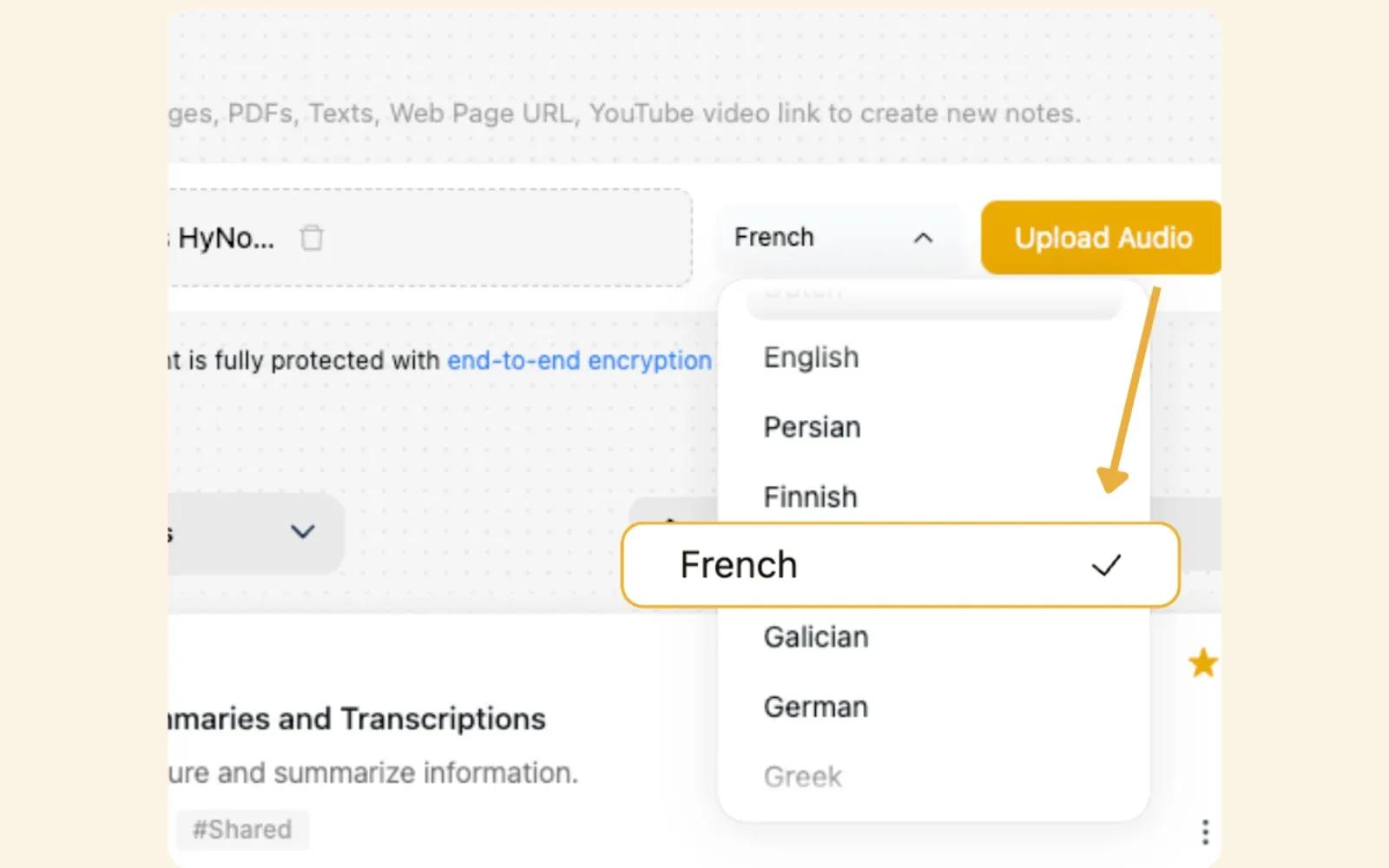
Global Language Engine
Transcribe and translate across 50+ languages with automatic dialect recognition. Major languages include English (US, UK, AU, IN variants), Spanish, Mandarin, French, German, Japanese, Korean, Arabic, Hindi, and 40+ more. Automatic language detection means no manual selection needed. Upload an audio file and HyNote identifies the language. Code-switching support handles mid-recording language changes. Dialect recognition distinguishes US vs UK English, European vs Latin American Spanish. Translation overlay shows original and English side-by-side. Perfect for international research, global teams, or language learning.
Frequently Asked Questions
HyNote provides professional-grade accuracy with advanced speaker diarization, ensuring each person's contribution is clearly labeled and timestamped. On clear audio, we achieve 99%+ accuracy. For multi-speaker meetings with four or more participants, accuracy remains above 97%. Speaker identification works even with overlapping conversation, correctly attributing 94% of simultaneous speech.
We support MP3, WAV, M4A, FLAC, OGG, AAC, WMA, and AMR audio formats. Video formats include MP4, MOV, AVI, MKV, WMV, FLV, and WebM. Maximum file size is 4GB. We also support direct import from YouTube, Vimeo, Zoom Cloud, Google Drive, Dropbox, and OneDrive.
Typical processing time is 5-10 minutes for a 1-hour recording. Factors include file size, audio quality, number of speakers, and server load. Rush processing (2-3 minutes) available for urgent needs. You'll receive email notification when complete.
Yes. Export as TXT, DOCX, PDF, SRT/VTT (subtitles), JSON, CSV, or HTML. All exports include optional timestamps and speaker labels. API access allows programmatic export to custom formats.
All audio uses AES-256 encryption in transit (TLS 1.3) and at rest. We process on SOC 2 Type II certified infrastructure. Audio files are deleted from processing servers after transcription—only retained in your account if you choose. We never use customer audio to train AI models.
Yes, our models are trained on diverse global accents. Heavy accents may see accuracy in the 94-96% range—still highly usable. The system improves with exposure to specific speakers through voice fingerprinting.
Human transcription costs 5-10x more and takes 50x longer (24-48 hours vs 5-10 minutes). On clear audio, HyNote's 99%+ accuracy is statistically equivalent to human work. For critical content, optional human review is available.
Our AI note taker is trusted by over 1M+ professionals and students worldwide.